Duolingo Local (unofficial)

Heja och välkommen! I have been on the journey of learning a new language for about four months now and have been having a blast with Duolingo. Recently I have also taken to a private teacher who has been helping accelerate my language learning journey in svenska. Why swedish you ask? Well I have some deep connections with Scandinavia and after spending some time abroad in Sweden, I absolutely fell in love with the country. The culture, the pace of living, the Scandinavian cold plunges into the Arctic Ocean, I love it all.
Recently I was on Duolingo, I have the paid version and have honestly been getting a lot out of their services, and I came to find that their vocab practice was not very well suited for how I wanted to study. They seemed to prioritize only words from my recent set of learned words and sometimes throwing in the occasional old word after awhile. They also only reiterate a small set of words in a single session so I don’t get a solid breadth of variety in my vocab study session.
Well, being a programmer and reverse engineer, I took to toying around a little with the Duolingo page on my laptop. I did the good ol’ “Open Developer Tools” -> “Go to Network Tab” -> “Open up the Duolingo Practice Hub” and then investigate what API calls were being sent to the Duolingo server. I came across one critical API call at https://www.duolingo.com/2017-06-30/users/<USER_ID>/courses/sv/en/learned-lexemes?limit=50&sortBy=ALPHABETICAL&startIndex=0 (you can also sort by LEARNED_DATE) which gave back a JSON response that looked like the following:
{
"learnedLexemes": [
{
"text": "absolut",
"translations": [
"absolutely",
"definitely",
"absolute"
],
"audioURL": "<URL>",
"isNew": false
},
{
"text": "acceptera",
"translations": [
"accept"
],
"audioURL": "<URL>",
"isNew": false
},
...
],
"pagination": {
"totalLexemes": 1707,
"requestedPageSize": 50,
"pageSize": 50,
"previousStartIndex": null,
"nextStartIndex": 50
}
}
I don’t want to go around dumping and distributing all of Duolingo’s data, so I’m doing my best to limit what I put here in my blog post
After observing the nice data that I get back from Duolingo, I wrote up a quick script (using my private cookies + data) that would hit that API with a ?limit=<totalLexemes> so ?limit=1707 to get back all of my learned words in one request. You could also just implement that with paging like they do for the website, but they let me get it all back in one request so why not :shrug:? You can do something similar by doing a “Right click on the network request” -> “Copy” -> “Copy as cURL” at least in Google Chrome and it will copy all the right headers and data sent for you to repeat call it.
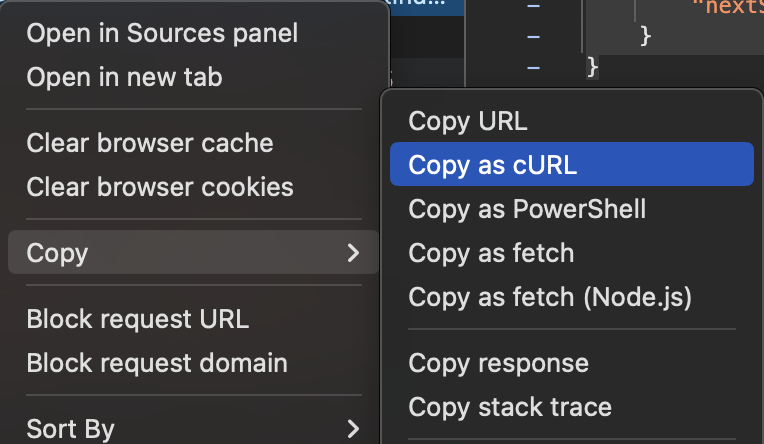
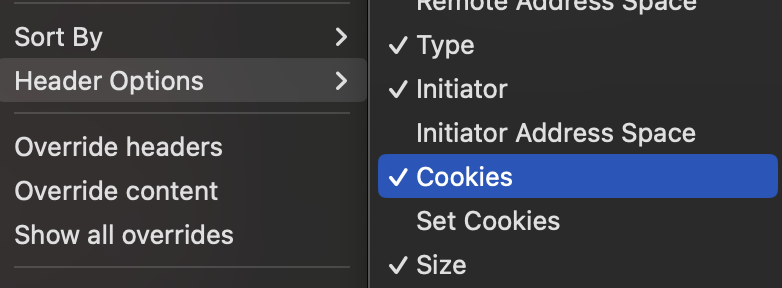
You may have to also toggle on the add cookies to the headers before you copy the cURL command. That enabled me to free run and experiement on my local machine and do a sort of download_word_dump.sh > word_dump/word_list.json to collect all my learned words!
Now okay, we have this nice and fun list, where do we go from here? Well my original thought was to just take this list and turn them into flash cards/show my swedish teacher which words I’ve learned so far on Duolingo so she doesn’t have to keep guessing what I do/don’t know. I decided to have a little bit more fun with it and create a super simple quiz study program via python.
Now, Duolingo provides those audio files which are open to the public to download if you have the URL (which comes back from the JSON payload.) Again, I’m doing my best to ride the line here so this is all just sitting on my local machine and I’m not intending to distribute this anywhere. I wrote up a quick script to parse the JSON payload, and download the sound file locally so I could make a nice practice script. I am also actively giving money to Duolingo so there is that (please Duo, don’t come after me, I’m smol potatoes.)
Here’s a super simple shell script using jq to parse the word dump file and download the audio files to a folder called audio_dump/.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
input_files=word_dump/*
# iterate over all the learned words dump
jq -r '.learnedLexemes[] | "\(.audioURL),\(.text)"' $input_files | while read data; do
audioURL=$(echo $data | awk -F, '{print $1}')
raw_text=$(echo $data | awk -F, '{print $2}')
# replace any spaces in the phrase with underscores
text=$(echo ${raw_text// /_})
# print out the word for visual progress
echo $text
curl $audioURL -o audio_dump/$text.mp3
done
So now that we have our words, we have our translations, and we have our sound files, what next? I then stumbled upon a really cool small python library called playsound which works perfectly for slapping together a simple python script to accomplish my study goals. So let’s get to it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
import json
from playsound import playsound
from pathlib import Path
import random
from typing import Dict, List
input_dir = "word_dump"
audio_dir = "audio_dump"
class bcolors:
HEADER = '\033[95m'
OKBLUE = '\033[94m'
OKCYAN = '\033[96m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
# Load the data into a dictionary to randomly sample from
word_list = {}
pathlist = Path(input_dir).glob('**/*.json')
for path in pathlist:
with open(path, "r") as f:
word_data = json.load(f)
for learned_word in word_data["learnedLexemes"]:
word_list[learned_word["text"]] = learned_word["translations"]
words = list(word_list.keys())
def play_sound(word: str):
"""Small wrapper function to play a sound from a known source location"""
playsound(Path(audio_dir) / f"{word.replace(' ', '_')}.mp3")
def ask_question(word_list: Dict, words: List[str]) -> List[str]:
"""Ask a word/phrase, play the audio file, and return the answers"""
word = random.choice(words)
print()
print(bcolors.BOLD + f"Translate: {word}" + bcolors.ENDC)
# play the audio file for this word
play_sound(word)
return word_list[word], word
num_right = 0
num_wrong = 0
total = 0
# kick off the study session
answers, word = ask_question(word_list, words)
question = bcolors.HEADER + "Type your answer ('r' to repeat 'q' to end session): " + bcolors.ENDC
user_input = input(question)
while user_input.lower() == "r":
play_sound(word)
user_input = input(question)
while user_input.lower() != "q":
total += 1
if user_input in answers:
print(bcolors.OKGREEN + "Correct!" + bcolors.ENDC)
num_right += 1
else:
correct_answers = "\n\t" + "\n\t".join(answers)
print(bcolors.FAIL + f"Incorrect :( Answers: {correct_answers}" + bcolors.ENDC)
num_wrong += 1
answers, word = ask_question(word_list, words)
user_input = input(question)
while user_input.lower() == "r":
play_sound(word)
user_input = input(question)
print("Tack för att du pluggade idag!")
if total:
print(f"""
{bcolors.OKBLUE} Your stats this session: {bcolors.ENDC}
{bcolors.OKGREEN} Number right: {num_right} {num_right/total * 100:.2f}% {bcolors.ENDC}
{bcolors.FAIL} Number wrong: {num_wrong} {num_wrong/total * 100:.2f}% {bcolors.ENDC}
{bcolors.BOLD} Total practiced: {total} {bcolors.ENDC}
""")
Now there is a lot here that could be iterated on and cleaned up, but I scoped this fun little project to a couple hours to have some fun and see what the Duolingo local (unofficial) experience could look like. Let’s check this out in action!
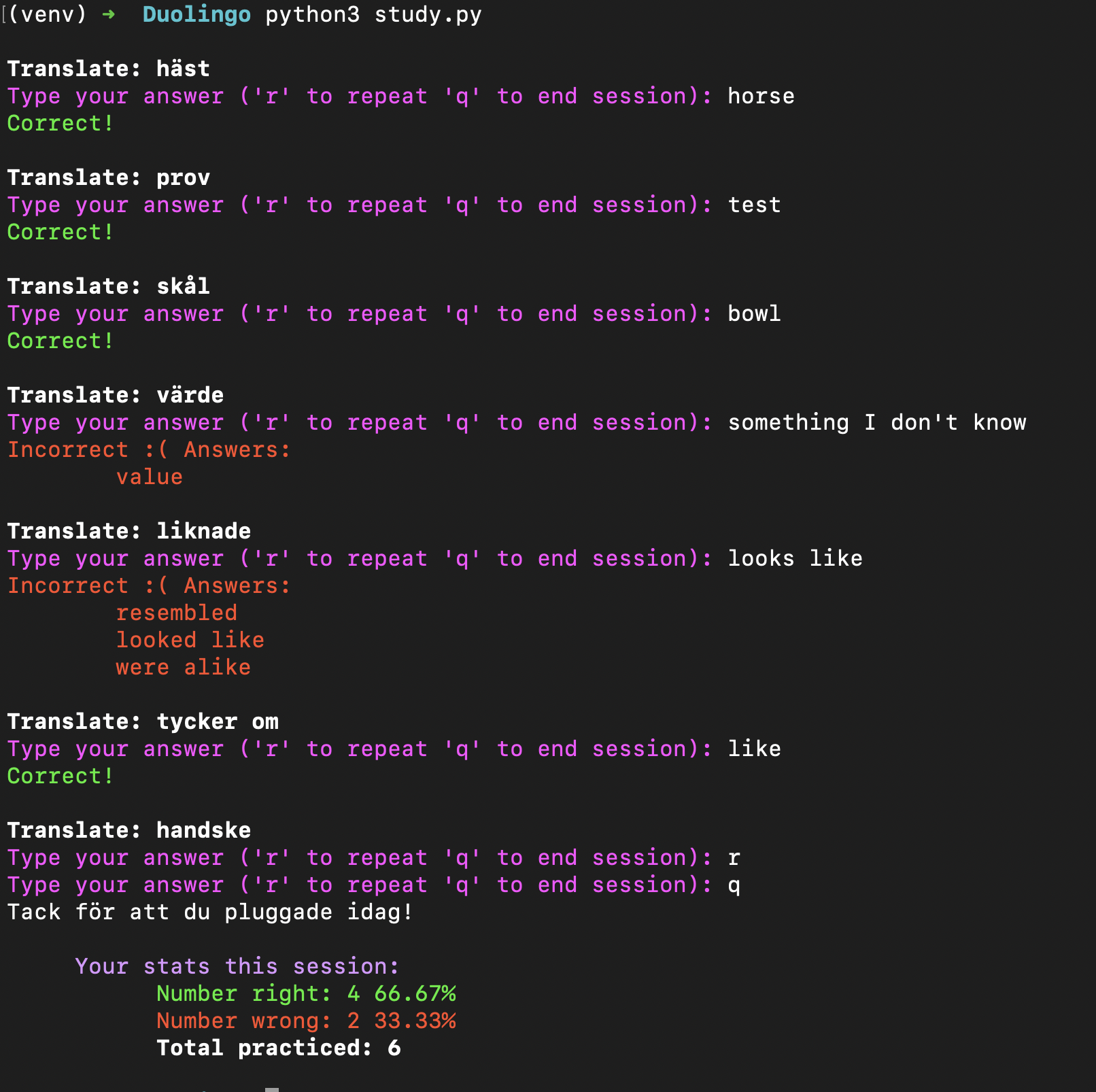
Some things that would be nice to iterate on:
- Add in some better/more variations to the
translationslist in the python program to account for how Duolingo handles “typos” - Add a “fail loop” for 3 or so times where you can try again if you missed the word
- Add in a statistic sampling of the words and save it off to a file on disk so you can reload.
- This would be something like keeping track of missed words, how often you’ve seen the words and so on. This would give the student a better sampling of words they need to practice.
- During the session, keep track of missed words and randomly sample from them periodically to practice the immediately missed words. This is what Duolingo does a lot in their normal lessons and I really like that feature of practicing the recently missed words.
Tack för att du läser min artikel, och vi ses snart!
Hej då!